

Google розширює лінійку власних моделей штучного інтелекту Gemini. Компанія презентувала Gemini 3.1 Flash-Lite – найекономнішу модель у серії Gemini 3, створену для швидкої роботи та обробки великих обсягів завдань.
Новинка орієнтована насамперед на розробників, яким потрібні масштабовані інструменти з мінімальною затримкою відповіді та низькою вартістю використання.
У Google наголошують, що Flash-Lite розроблена для високочастотних робочих процесів, де важлива оперативність генерації результатів. Модель оптимізована для автоматизованих систем, які працюють із великими обсягами даних і потребують швидкої реакції.
Вартість використання сервісу залишається однією з головних переваг нової моделі. Обробка одного мільйона вхідних токенів коштує $0,25, тоді як генерація одного мільйона вихідних токенів обійдеться у $1,50.
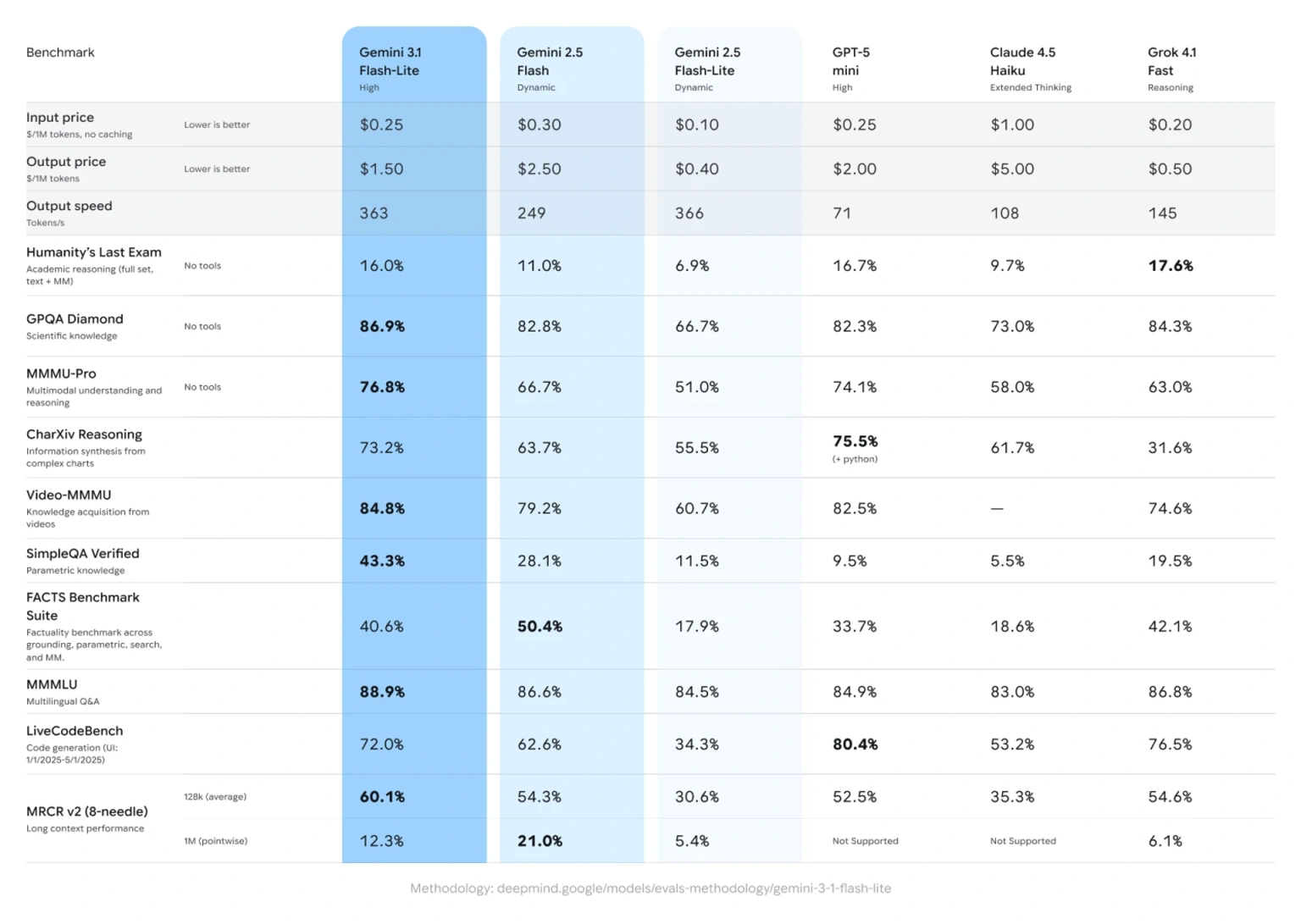
За результатами бенчмарку Artificial Analysis, Gemini 3.1 Flash-Lite демонструє значно швидший старт генерації відповіді. Показник Time to First Answer Token у неї приблизно у 2,5 раза швидший порівняно з моделлю 2.5 Flash.
Крім того, швидкість створення тексту збільшилася на 45%, при цьому якість відповідей зберігається на подібному або навіть кращому рівні.
У рейтингу Arena.ai Leaderboard нова модель отримала оцінку Elo 1432. Під час спеціалізованих тестувань вона показала конкурентні результати:
- 86,9% у тесті GPQA Diamond
- 76,8% у MMMU Pro
За цими показниками Flash-Lite змогла випередити низку моделей того ж класу і навіть деякі більші системи попередніх поколінь.
У Google позиціонують Gemini 3.1 Flash-Lite як інструмент для масштабних та регулярних операцій, де важлива швидкість обробки і економічність.
Зокрема, модель може застосовуватися для:
- масового перекладу текстів
- модерації контенту
- класифікації даних
- аналізу великих кодових баз
- виконання масштабних мультимодальних завдань
Наразі Gemini 3.1 Flash-Lite уже доступна в режимі preview. Розробники можуть протестувати її через Gemini API у середовищі Google AI Studio, а корпоративні клієнти – через платформу Vertex AI.
Таким чином Google робить ставку на більш доступні та швидкі AI-моделі, які можуть обслуговувати масові робочі процеси без значних витрат на обчислення.





